前记
面了这么多家,也就网鱼那此问到了这些东西,我直接都跳过了。
阻塞和非阻塞
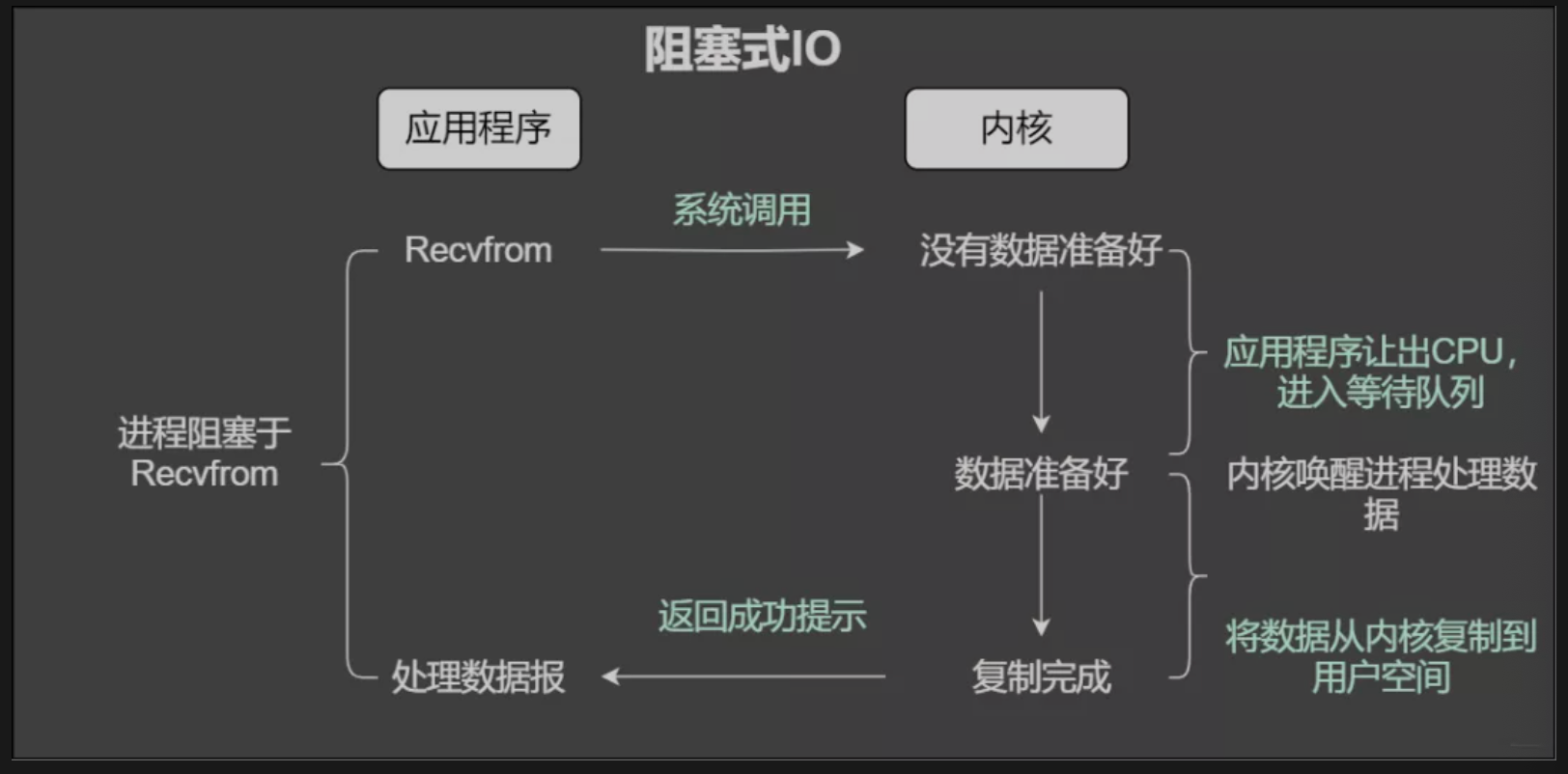
通过阻塞的IO获取输入数据,每个连接都用独立的线程完成数据输入,业务处理以及数据返回的操作
带来的问题就是,并发量大的时候,需要大量的线程来处理,占用大量的系统资源。连接建立后,如果当前线程没有数据可读,将会阻塞在read操作上造成线程资源的浪费
IO复用模型
所谓IO复用即多个线程共享一个阻塞对象,应用程序只会在一个阻塞对象上等待、当某个连接有新的数据处理,数据系统直接通知应用程序,线程从阻塞状态返回并开始业务处理
线程池复用方式
将连接完成后的业务处理任务分配给线程,一个线程处理多个连接的业务。IO复用结合线程池的方案即Reactor模式
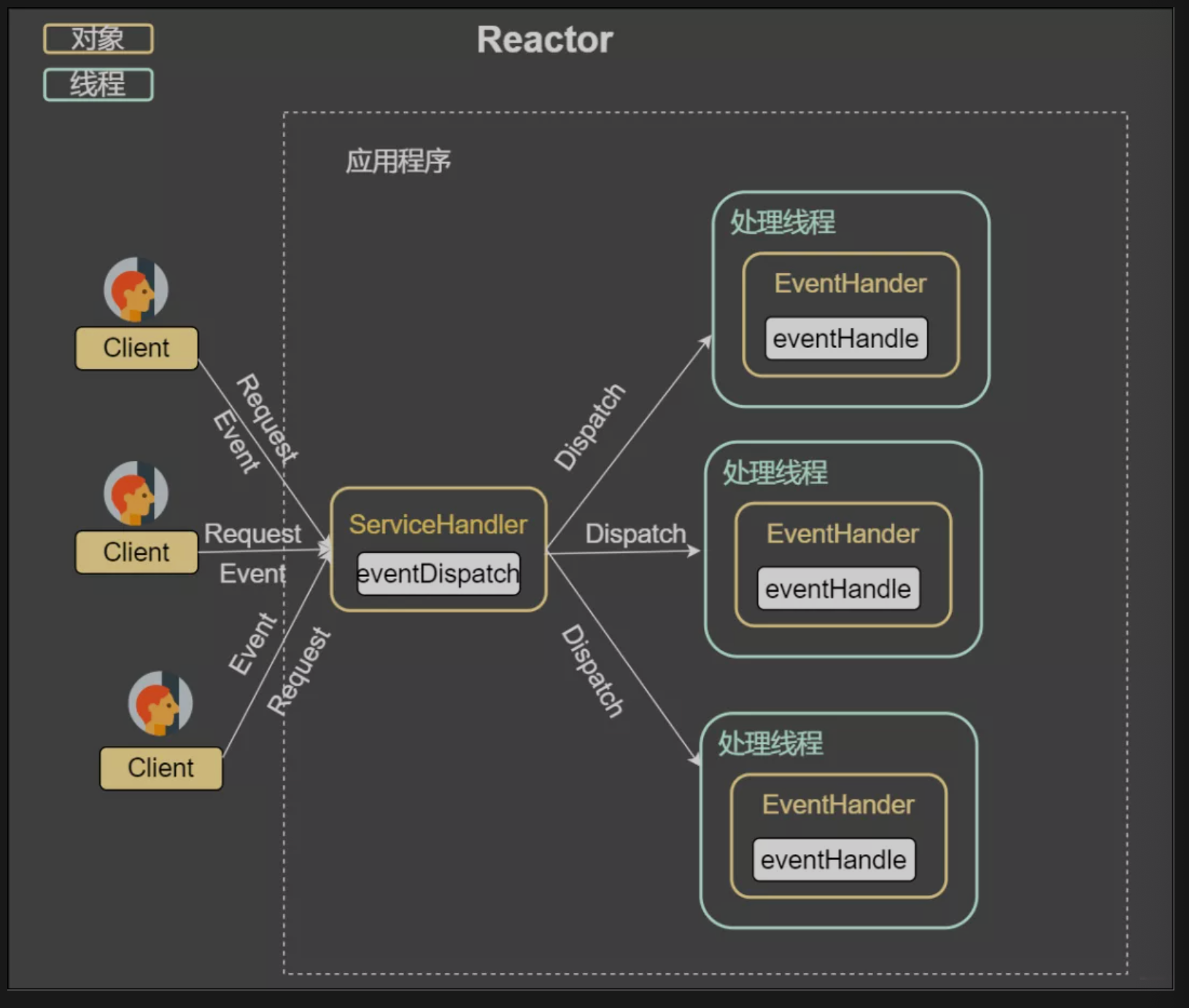
上图可以发现,通过一个或者多个请求传递给服务器,通过统一的事件管理机制进行请求分发,这种模式即为 事件驱动处理模式
通常服务端处理网络请求的过程是什么样的
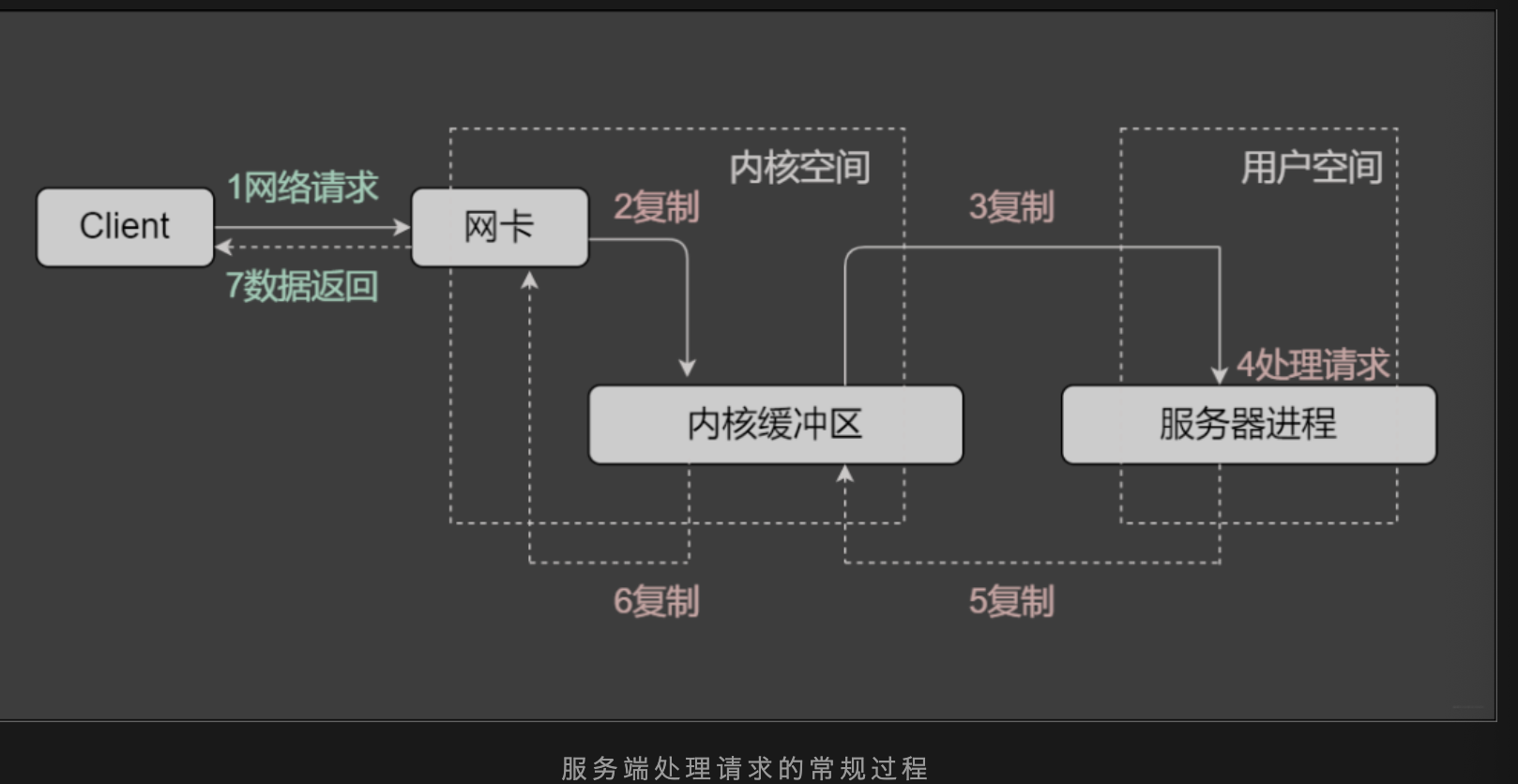
Reactor
在一个单独的线程运行,主要负责监听和分发事件。类似于我们手机设置的转接
非阻塞
当使用非阻塞函数时,和阻塞IO类比,内核会立即返回,返回后获得足够的CPU事件继续做其他的事情
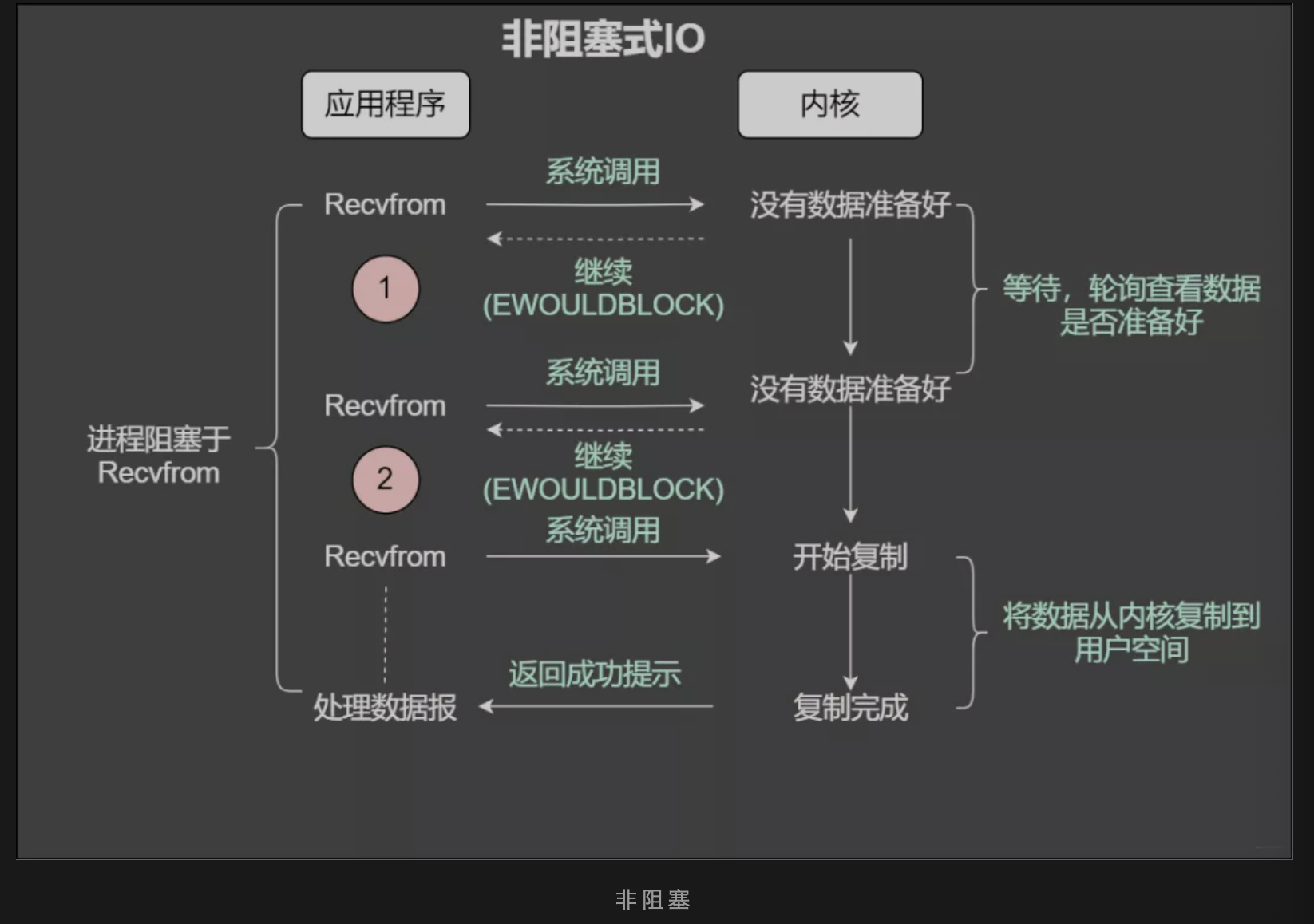
非阻塞IO之读
套接字有个缓冲区,如果缓冲区没有数据可读,那么在非阻塞的情况下调用read就会立即返回,返回一个状态。可能是 EWOULDBLOCK 或者 EAGAIN 出错信息
非阻塞IO之写
发送缓冲区,如果发送缓冲区满了,不能容纳更多的字节,这时候操作系统内核就会尽全力从应用程序拷贝数据到发送到发送缓冲区并立即从write调用返回。在拷贝的过程中,可能全部拷贝了,也可能一字节也没拷贝,所以使用返回值来告诉应用程序到底有多少数据拷贝到了发送缓冲区,方便再次调用write 输出未完成的字节
阻塞IO和非阻塞IO的区别

总结如下
- read总是在接受缓冲区有数据的时候直接返回,而不是等到应用程序数据充满才返回。如果此时缓冲区是空的,那么阻塞模式下就会等待,非阻塞会返回-1并有EWOULDBLOCK或EAGAIN错误
- 和read不太一样,在阻塞模式下,write只有在发送缓冲区足以容纳应用程序的输出字节时才会返回。在非阻塞的模式下,能写入多少写入多少,并返回实际写入的字节数
当使用fgets等待标准输入时,如果此时套接字有数据但不能读出。IO多路复用意味着可以将标准输入,套接字等都当做IO的一路,任何一路IO有事件发生,都将通知相应的应用程序去处理相应的IO时间,在我们看来就是反复同时可以处理多个事情,这就是IO复用
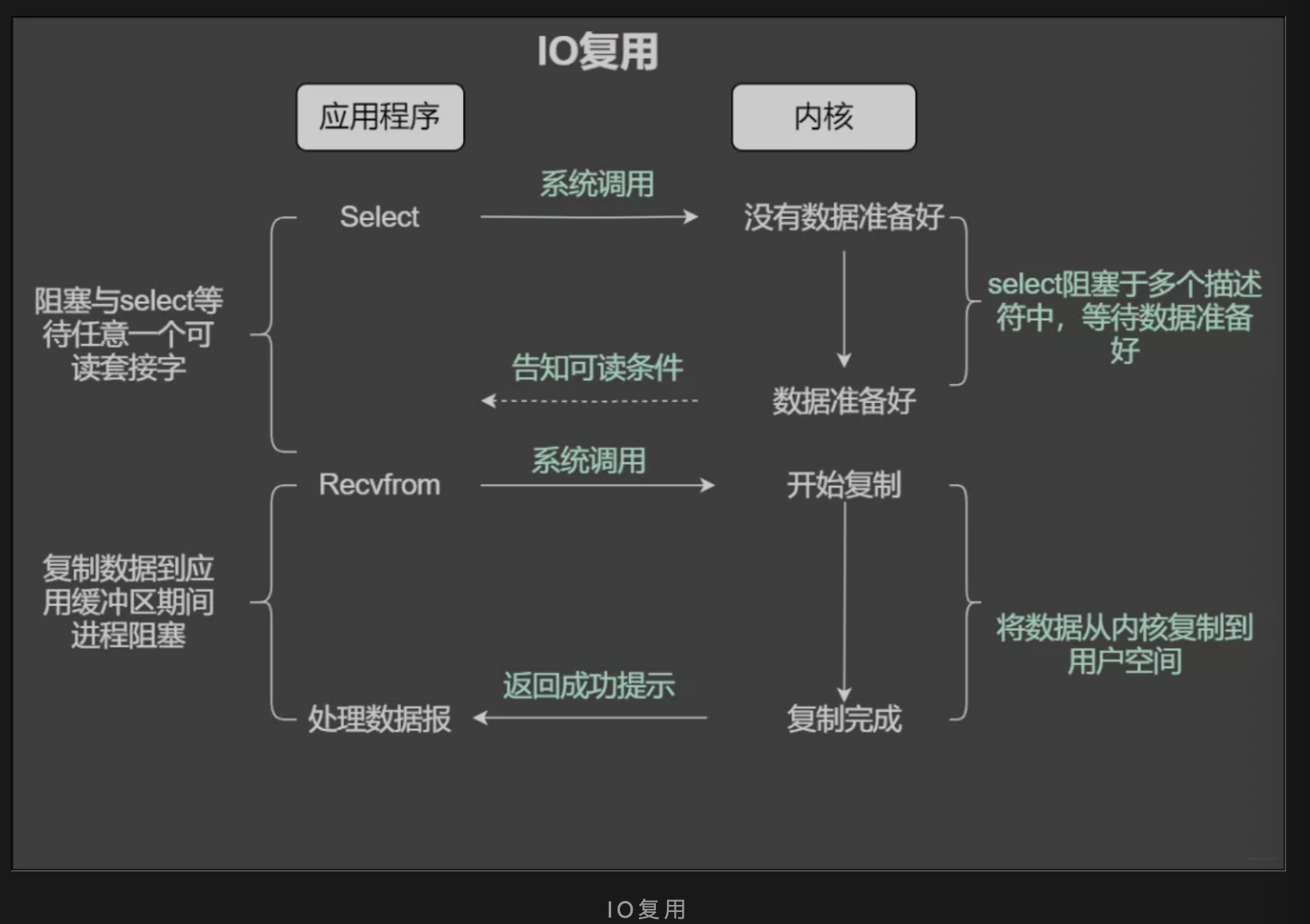
select
当使用select的时候,先通知内核挂起线程,一但一个或者多个IO事情发生,控制权将返回给应用程序,然后由应用程序进行IO处理