前记
最近还是收到了不少offer,掌门一对一,太平洋房屋,爱库存。其实面试都大同小异,却又很不同,好几位面试官给我留下了很深刻的印象,但我是实在太笨了,没有做到很好的吸收。
最近也发现了个可以快速进行复习的小窍门,那就是敲键盘-记笔记 :」
redis持久化机制
redis通过持久化把内存中的数据同步到硬盘文件中来保证数据持久化。当redis重启后通过硬盘文件重新加载到内存,就能达到恢复数据的目的
RDB:按一定时间周期策略把内存的数据以快照的形式保存到硬盘的二进制文件。及snapshot快照存储,对应产生的数据文件为dump.rdb 通过配置文件中的save参数来定义快照的周期。具体实现:单独创建fork()一个子进程,将当前父进程的数据库数据复制到子进程内存中,由子进程写入到临时文件中,持久化过程结束了,再用这个临时文件替换上次的快照文件,然后子进程退出,释放内存
AOF:redis会将每一个收到的命令通过write函数追加到文件最后,类似于mysql中的binlog。当redis重启是会通过重新执行文件中保存的写命令来再内存中重建数据库的内容
缓存常见问题
缓存雪崩
设置了相同的过期时间,同一时刻出现大面积的缓存过期
加锁,或者队列保证不会有大量的线程对数据库一次性进行读写,或者将缓存过期时间分散
缓存穿透
缓存中没有
采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中。或者查询返回的数据为空,我们会把结果放到缓存,但过期时间会很短,这样第二次到缓存中获取就有值了,
缓存预热
- 数据量不大,启动项目时自动加载
- 定时刷新缓存
缓存更新
- 定时清理过期缓存
- 当有用户请求过来时,判断是否过期
缓存降级
缓存的读写模式
Cache Aside Patter
旁路缓存,是最经典的缓存+数据库读写模式
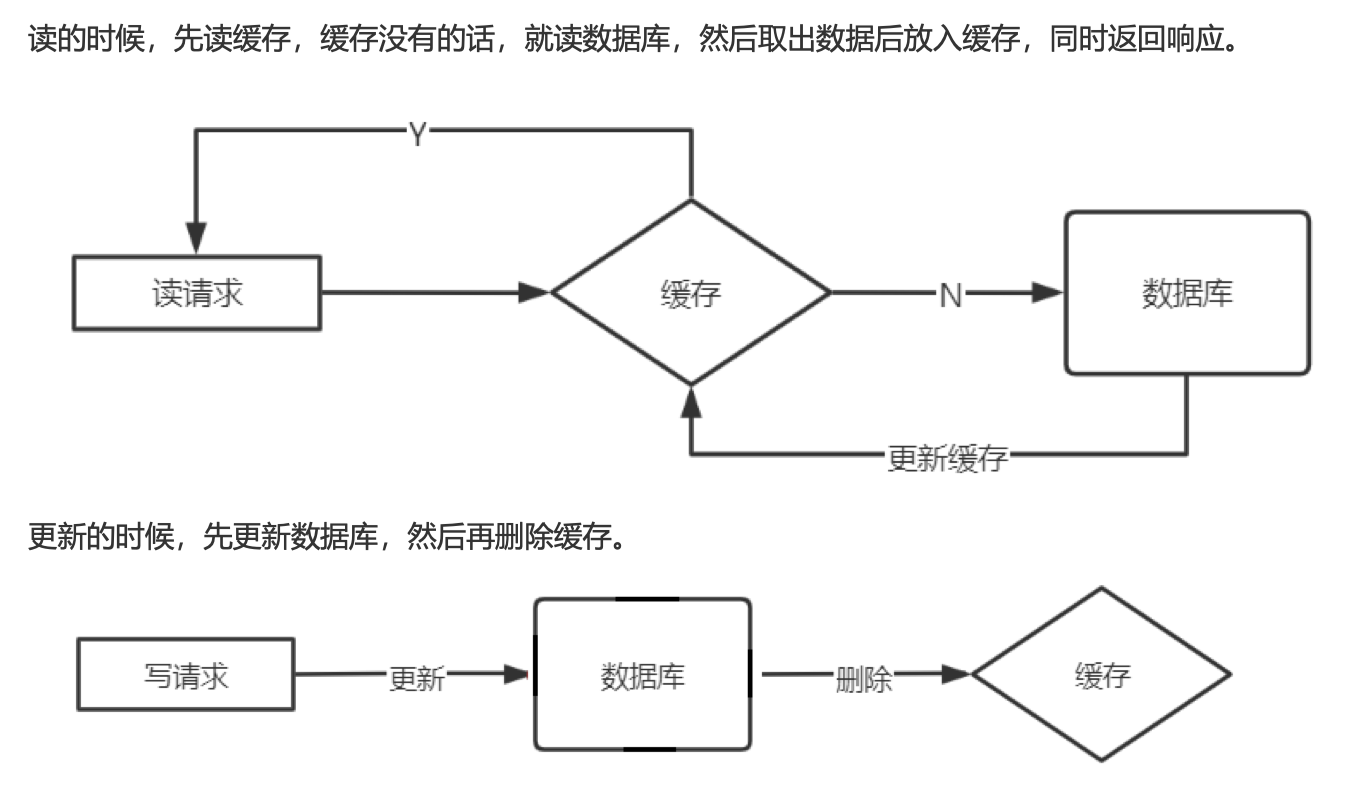
-
为什么是删除缓存,而不是更新缓存
- 缓存的值是一个结构:hash list 更新数据库需要遍历
- 这是一种懒加载模式,使用的时候才更新缓存。当然也可以采用异步的方式填充缓存
-
高并发脏读的三种情况
- 先更新数据库,再更新缓存
- 先删除缓存,再更新数据库
- 先更新数据库,再删除缓存(推荐)
-
保证数据的最终一致性:延时双删
- 先更新数据库同时删除缓存,等读的时候再填充缓存
- 2秒后再删除一次缓存
- 设置缓存过期时间,比如10秒或1小时
- 将缓存删除失败记录到日志中,利用脚本提取失败的记录再次删除(缓存失效期过长7*24)
升级方案
通过数据库的binlog来异步淘汰key,利用工具 canal 将binlog日志采集发送到MQ中,然后通过ACK机制确认处理删除缓存
redis常见的坑
- 过期时间
- key value 不能过长
- 保证内存占用不会很高
redis数据并发竞争
指多个redis的client同时set同一个key,引起的并发。比如本来按顺序修改为 2 3 4,最后是4,但是并发最后成了2
分布式锁+时间戳
准备一个分布式锁,大家去抢锁,抢到锁就做set操作。用到zookeeper + redis
先从zookeeper尝试获取锁,只有获取到了才能操作,redis中保存的value是时间戳,获取到并且时间戳大于此key才可以操作
利用消息队列
可以通过到消息中间健进行处理,把并行消息读写进行串行化
HOT KEY
如何发现HOT KEY
- 预估
- 客户端统计
- 大数据监控
如何处理HOT KEY
- 变分布式缓存为本地缓存 利用 Ehcache, Guava Cache
- 每个redis主节点都备份hot key 数据
- 利用热点数据访问的限流熔断,每个形同每秒最多缓存请求不超过400次,一超过就可以熔断掉
BIT KEY
常见场景
- 热门话题下的讨论
- 大V的粉丝列表
- 序列化后的图片
- 没有及时其清理的垃圾数据
BIT KEY 的影响
- 占用内存
- redis性能下降,主从复制异常
- 在主动删除或过期删除时会操作过长引起服务阻塞
如何发现
- Redis-cli –bigkeys 可以找到某个实例5中类型最大key
- 获取生产的redis RDB文件,通过 rdbtools 分析生成 CSV文件,再导入mysql或者其他数据库进行分析,根据size_in_bytes统计
如何处理
优化big key 的原则就是string减少字符串长度, list hash set zset 减少成员数
-
String 类型的big key 可以存到数据库或者CDN
-
单个 key value 很大,可以分成几个key value 使用 mget获取
-
Hash, set , zset list 可以分拆(常见)

- 删除big key 不要用del,因为del是阻塞命令
- 使用 lazy delete (unlink)命令 该命令会在另一个线程中回收内存
zset底层原理
元素小于128个 && 所有member长度都小于64字节 ==》 使用 ziplist :第一个将节点保存member,第二个保存score
否则使用 skiplist,底层是一个命名为zset的结构体,而一个zset结构同事包含一个字段和一个跳跃表。跳跃表按score从小到大保存所有元素集合,而字典保存着从member到score的映射,这样就可以用O1的复杂度来查找member对应的score值,虽然同时使用俩种结构,但他们会通过指针来共享相同元素的member和score,因此不会浪费额外内存