前记
这个系列更多的是在总结和陈述重点,让面试官有😯,这家伙一定懂了的感觉
说说dubbo
是一个高性能,轻量级的开源 java RPC 框架
三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现
什么是RPC
remote Procedure Call 远程过程调用,相对应的是本地过程调用,用来作为分布式之前的通信,可以用http来传输,也可以基于TCP自定义传输协议
RPC和http的区别
http和RPC并不是一个并行概念。RPC是远程过程调用,其调用协议通常包含传输协议和序列化协议
- 传输协议: http2协议,也有如dubbo一类的自定义报文的tcp协议
- 序列化协议:基于文本编码的xml json 也有二进制编码的 protobuf hessian 等
为什么要使用自定义tcp协议的RPC做后端进程通讯
http使用的tcp协议,和我们自定义的tcp协议在报文上的区别:
-
不是连接的建立与断开,http协议是支持连接池复用的
-
http也可以用使用protobuf这种二进制编码协议对内容进行编码
-
二者最大的区别还是在传输协议上
自定义tcp协议的报文,报头占用的字节数也就只有16个byte,极大的精简了传输内容。这也就是为什么后端进程间通常会采用自定义tcp协议的RPC来进行通信的原因 ==》 因为良好的RCP调用是面向服务的封装,针对服务的可用性和效率等都做了优化。单纯使用http调用则缺少了这些特性
你们公司是怎么用到的dubbo
我们公司的SOA产品,Service Oriented Architecture 面向服务的架构
-
首先是用户面对的应用层,就是一些对外的接口
-
然后会调用业务层,封装全部的业务需求,比如开通vip,注册商家商品等
-
基础的业务层 比如账号基础服务
-
基础的服务层
与业务无关的模块,请求量大,逻辑简单,比如消息服务(发邮件,短信等)
-
存储层 mysql es 等
利用dubbo单项调用,可以跨层调用,但不能 逆向
利用 dubbo-monitor 来监控服务
dubbo具体是怎么运行的
分为4个部分
- registry(zookeeper)
- provider
- consumer
- monitor
说说流程:
- Provier在服务容器启动时,向注册中心注册自己提供的服务
- consumer启动时,向registry订阅自己所需要的服务
- registry返回provider提供的地址列表,如果有变动,registry会基于长连接推送变更的数据给消费者。 consumer从提供者地址列表中,基于负载均衡选一台provider进行调用
- provider consumer 在内存中的调用次数和时间定时每分钟发送给monitor
SPI熟悉吗
spi Service Provider Interface 是JKD内置的一种服务提供发现机制,扩展发现
是一种动态替换发现机制,实现解耦,使得第三方服务模块的装配控制逻辑与调用者的业务代码分离
我先说一下 JDK中的SPI
首先需要提供标准的服务接口,再提供相关接口实现和调用者,就可以通过SPI机制中约定好的信息进行查询相应的接口实现
我再细说一下:
- 在 META-INF/services目录下创建一个以“接口全限定名”命名的文件,内容为 实现类的全限定名
- 接口实现类所在的jar包放在主程序的classpath中
- 通过 java.util.ServiceLoader动态装载实现模块,它通过扫描 META-INF/services目录下的配置文件找到实现类的全限定名,把类加载到JVM中
- SPI的实现类必须携带一个无参构造方法
dubbo中的SPI
通过实现统一接口的前提下,定制自己的实现类,比如常见的协议,负载均衡等都可以自己扩展
dubbo自己做SPI的目的
- JDK标准的SPI 会一次性实例化所有实现,耗时,浪费资源,而dubbo中给每个实现类配了个名字。通过名字去文件中岛对应的类实例化,按需加载
- 如果有扩展点加载失败,则所有扩展点无法使用
- 提供了对扩展包包装的功能(Adaptive) 并且还支持set方式对其他扩展点注入
dubbo SPI中的Adaptive功能
主要解决的是如何动态的选择具体的扩展点,通过url的方式对扩展点进行动态选择
对所有的扩展点进行封装为一个类,通过url传入参数时的动态选择需要的扩展点,底层原理是动态代理
通过实现 Filter 接口,可以做日志记录,监控功能,
说说dubbo中负载均衡
主要用于consumer中存在多个provider
- 随机(默认)
- 轮询
- 最少活跃数用书
- 一致性hash
dubbo的线程池
fix 和 cache
可以自定义线程池,利用SPI给fix线程池加扩展,监控
http 和 RPC的区别
http是一个传输协议,协议比较冗余
RPC基于TCP自定义协议
说一下服务暴露的流程
首先provider启动,通过proxy组件根据具体的协议protocol将需要暴露出去的接口封装成Invoker,然后再通过Exporter包装一下,这是为了在注册中心暴露自己套的一层,然后将Exporter通过Registry注册到注册中心
以下是细节
spring IOC容器刷新完毕后,会根据配置组装URL,根据url的参数来进行本地或者远程调用。通过proxyFactory.getInvoker 利用javassist进行动态代理,封装真的实现类,通过url参数选择对应的协议来进行Protocal.export,默认是dubbo协议。
第一次暴露会调用createServer 创建 Server 默认是 NettyServer、将export得到的exporter存入一个map中,供之后的远程调用查找,然后会向注册中心注册提供者的信息
服务暴露全流程
- 从代码的角度
- 检测配置,如果有些配置空的话会默认创建,并且组装成URL
- 服务暴露,包括暴露到本地的服务和远程的服务
- 注册服 务至注册中心
- 从对象构建转换的角度
- 将服务实现类转成Invoker
- 将invoker通过具体协议转换成Exporter
服务引入的流程
俩种方式
-
饿汉式
加载完毕就引入
-
懒汉式(默认)
只有当这个服务被注入到其他类中时,启动引入流程
会先根据配置参数组装成url,会构建RegistryDirectory向注册中心注册消费者信息,并且订阅提供者,配置,路由节点等、得知提供者信息之后会进入Dubbo协议引入,会创建Invoker,期间会包含NettyClient,来进行远程通信,最后通过Cluster来包装Invoker 默认是FailoverÇluster 最终返回代理类
服务调用的流程
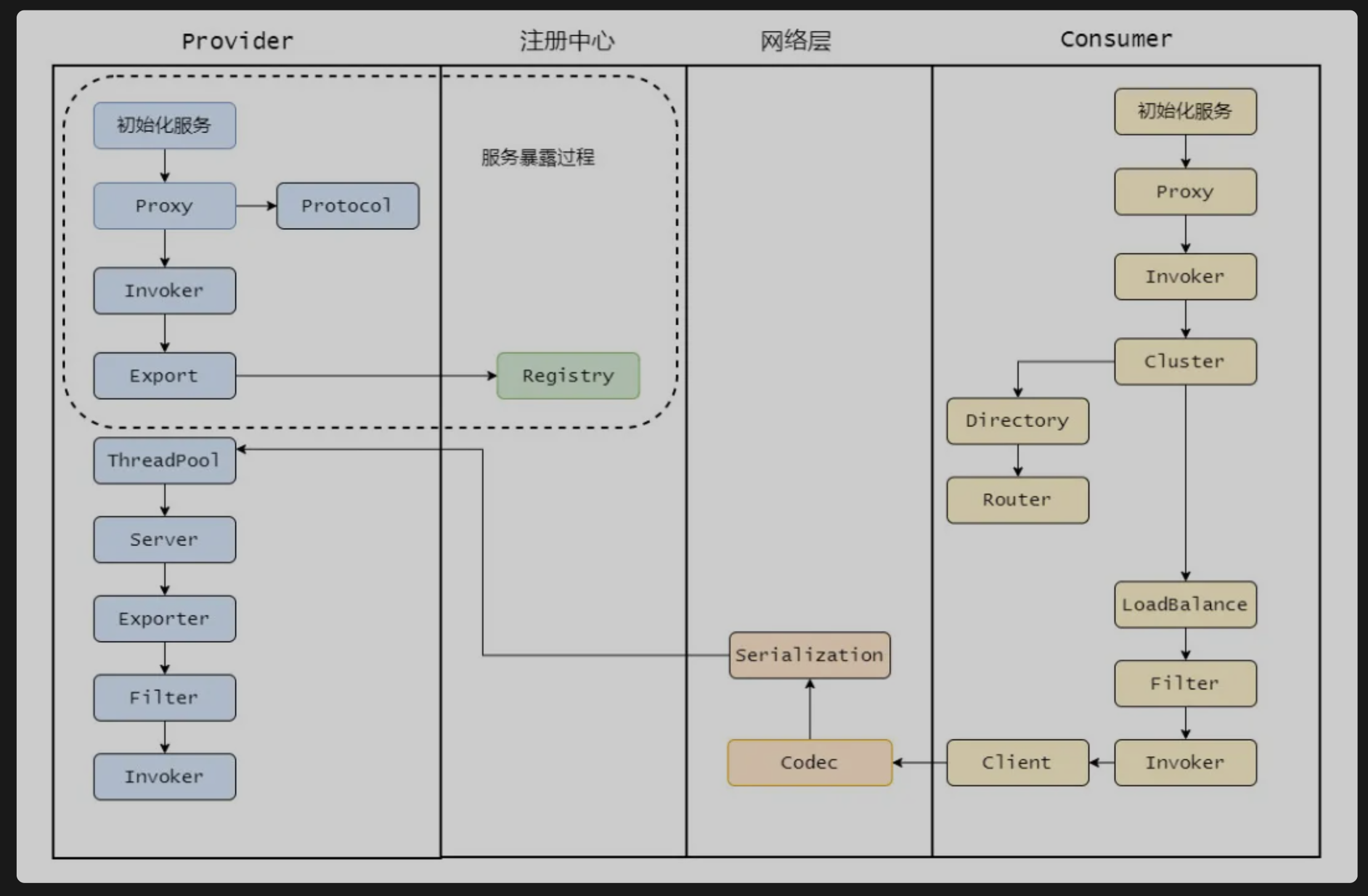 .
.
首先消费者启动会向注册中心拉取服务提供者的元信息,然后调用流程也是从proxy开始,proxy持有一个Invoker对象,调用invoker之后需要通过cluster线程Directory获取所有课调用的invoker列表,如果配置了某些路由规则,比如某个接口只能调用某个节点,那就再过滤一遍invoker列表。剩下的invoker再通过loadBalnce做负载均衡选取一个,再经过filter做一些统计什么的,再通过client做数据传输,比如netty,传输要经过Codec接口做协议构造,再序列化。最终发往对应的服务提供者。
服务提供者接收到之后也会进行Codec协议处理,然后反序列化将请求扔到线程池处理,某个线程会更具请求找到对应的Exporter,而找到Exporter其实就是找到了Invoker,但是还会有一层层Filter,最终调用实现类然后原路返回结果
————- 以下细节
调用某个接口的方法会调用之前生成的代理类,然后会从cluster中经过路由的过滤,负载均衡机制选择一个invoker发起远程调用,此时会记录请求的ID等待服务端的相应
服务端接受请求之后会通过参数找到之前暴露存储的map,得到相应的exporter,然后最终调用真正的实现类,再组装好返回结果,这个相应会带上之前请求的ID
消费者收到响应之后会通过ID去找之前记录的请求,然后找到请求之后将响应塞到对应的Future中,唤醒等待的线程,最后消费者得到相应
如何设计一个RPC框架
手先需要实现高性能的网络传输,可以采用netty来实现,需要自定义协议,然后需要定义好序列化协议,因为网络的传输都是二进制流传输的
然后可以搞一套描述服务的语言,IDL (Interface description language) 让所有的服务都用IDL定义,再用框架转换为特定编程语言的接口,这样就能跨语言了
需要把上述的细节对使用者屏蔽,需要用代理实现。还需要实现集群功能,因此要服务发现,注册等功能。最后还需要一个监控机制,埋点上报调用情况等