前记
这个系列的文章是我在面试前所做的一项最终总结,文章内的字词话语尽量是针对面试现场的话术,也就是和面试官的正常对话。
面试kafka不一定问的很细 大部分是问raft 很多人自己kafka都没搞清楚
其实,不止重复消费。更重要是保证partition的有序性
zookeeper主要是作为分布式协同服务:共享存储–保证数据的一致性
下面说说zookeeper的应用场景
-
用zookeeper来存储一些常用且多变的配置数据,保证一致性。在zookeeper上选取一个节点用来存储数据,然后及集群中的每台机器在启动初始化阶段会读取上面存储的信息,还要注册一个watcher监听
-
利用临时节点,来监控主机状态
-
分布式日志收集系统
-
注册收集器机器
/log/collection/hostname1 每个收集器在启动的时候,都会在收集器节点创建自己的节点,这里是永久类型的,通过state节点来判断
-
在收集器节点上注册日志源机器列表
将日志源机器分别写到收集器机器节点(如 /log/collection.hostname1)上去
-
状态汇报
每隔收集器创建完成后,需要再子节点上创建一个状态子节点(/logs/collector/host1/status)每隔一点时间写入自己的状态信息以及负载(心跳检测机制)日志系统根据该状态来判断收集器是否存活
-
如果收集器机器挂掉或者扩容
日志系统时钟关注这 /logs/collector/节点的变更,一旦检测到变化,就将之前分配给收集器的所有任务进行转移—-根据汇报状态的负载进行转移
-
-
共享锁 临时顺序节点
/shared_lock/host1-R/W-0001
读请求 – 获取所有子节点 – 向比自己小的最后一个写请求注册监听
写请求– 获取所有子节点–向比自己序号小的最后一个节点注册
zookeeper 的选举机制
一定要奇数台节点
5台节点选举, myId分别为1-5
第一台myId为1启动,选举自己,
第二台myId:2启动,选举自己,2>1所以候选人是2
第三台myId:3启动,选举自己,3>1所以候选人是3,且超过半数,所以第三台当选leader
说说队列
主要用来解耦,削峰
比如一个订单系统,创建订单后,库存系统,支付系统,通知系统都会通过队列来解耦调用,防止因为一个子系统故障造成整个下单系统的瘫痪
系统遇到流量的猛增,会将系统压垮,详细队列将大量请求缓存起来
RocketMQ 大概是怎样的
由 Name Server , Broker , Producer , Custmer 构成
怎么保障消息可靠性
同步双写,异步复制到slaver
RocketMQ本质都是采用消费端主动拉取的方式
push方式:consumer把长轮询封装了,然后注册了一个监听器,收到消息后,唤醒长轮询来消费
提升写入性能
采用oneway方式,不用等待消费者返回确认
增加producer的并发量
提升消费性能
提高消费并行度(总的consumer数量不超过read queue)
以批量的方式消费
这里写写,突然想到的场景
我们当时消息在消费端出现了很大的堆积,通过修改producer consumer的并行度也不是很有效,然后就查了一下堆积的任务,大都是一些update这样的任务,想到了类似于kafka中的批量消费
首先要在producer端设置这类update任务的tag
通过tag的过滤,再设置consumeMessageBatchMaxSize 来批量update任务。
消息是存储在哪里的
目前主流的队列,都是采用消息刷盘至所部署机器的文件系统
rocketMQ消息用顺序写,600MB/s
存储的结构:
每个topic下的每message queue都对应一个索引 consumeQueue ,来指向e CommitLog
consumeQueue 记录了指定topic下的队列消息在commitLog中的起始物理偏移量,消息大小,消息tag的hashcode值
过滤消息
RocketMQ是在consumer端进行消息过滤的
- consumer端构建一个SubscriptionData发送一个pull消息给Broker端
- broker端从RocketMQ的文件存储层-store读取数据前,会构建一个MessageFilter,然后传给Store
- store从ConsumeQueue读取到一条记录后,会用他的消息记录tag Hash过滤
- 服务端根据hashcode进行判断,无法精确对tag原始字符串进行过滤,在consumer拉取到消息后,还需要对消息的原始tag进行对比
零拷贝原理
如何保证消息顺序
保证部分有效即可
a. 发送端把同一个业务的ID消息发送到同一个message Queue(hash取模)
消费过程中从同一个message Queue读取,使用MessageListenerOrderly类,为每个message Queue加锁,消费每个消息前,需要先获得这个消息对应的锁,保证同一个时间,同一个consumer Queue对的消费不背并发消费,但不同的consumer Queue的消息可以并发处理
事务消息
RocketMQ采用俩阶段提交的方式实现事务消息
https://developer.aliyun.com/article/771097
用rocketMQ实现 数据库+发消息 事务
实现一个 TransactionListener 接口,包括俩个方法:executeLocalTransaction, checkLocalTransaction
具体的就是利用俩阶段提交,在事务中,先执行数据库的操作,然后进入prepared状态,执行executeLocalTransaction方法,返回三个参数
- COMMIT_MESSAGE
进入俩阶段的第二阶段commited状态,可以消费这个消息
- ROLLBACK_MESSAGE
回滚,消息被删除,消费者不能消费这个消息
- UNKNOW
每隔一段时间调用一次checkLocalTransacrtion , 在BrokerConfig中可以配置,默认是1分钟,检查一次,最多5次
以上在操作过程中是有问题的,如果在service报错了,那么就会出现数据库回滚但是消息发出了,是因为数据库的隔离机制,在事务提交前是可读的,所以消息提交了。所以在 executeLocalTansaction 中固定返回 UNKNOW ,checkLocalTransaction 在 sendTransactionMQ 后执行,而且和 sendTransactionMQ 不在同一事务中
三个主流的消息队列的区别
从broker来说
-
暴力路由
kafaka为了提升性能,简化了MQ功能模型,仅仅提供了一些基础的MQ相关功能,但是大幅度优化和提升了吞吐量。一套服务集群,每台机器上都有一个kafka broker进程,负责接收请求,存储数据,发送数据
数据流模型,叫做topic,可以往这个topic写数据,然后让别人从这里来消费,可以划分为多个partition每个partition放一台机器上,存储一部分数据。在写消息到topic的时候, 会自动把你这个消息给分发到某一个partition上去。在消费消息的时候,部署在多个机器上的consumer可以组成一个group,一个partition只能给一个consumer消费,一个consumer可以消费多个partition,这是最核心的点。
通过这个模型,保证一个topic里的每条数据,只会交给consumer group里的一个consumer来消费,形成了一个queue
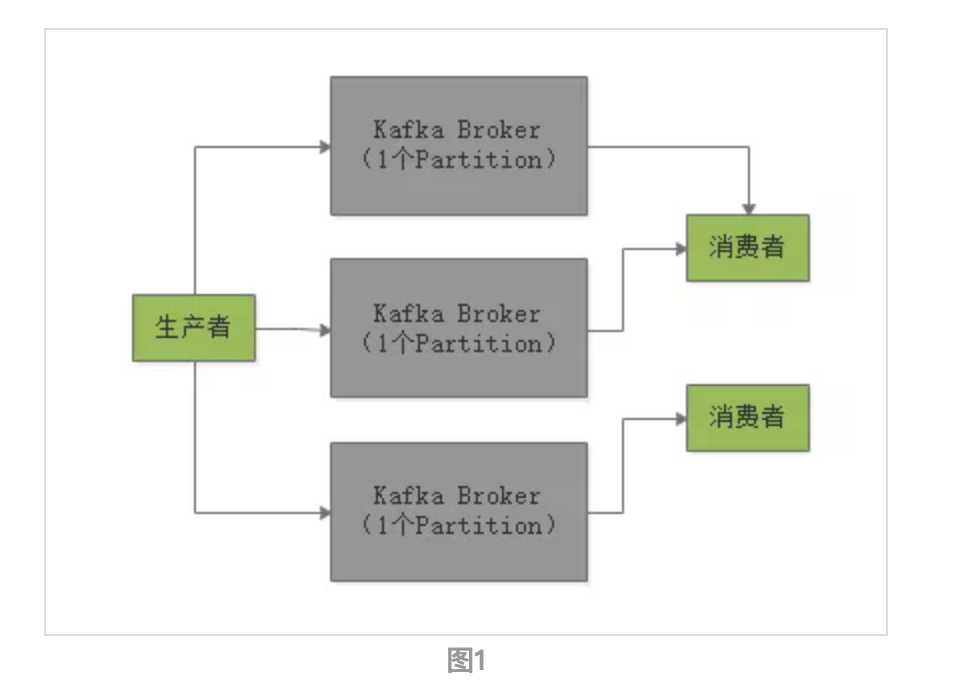
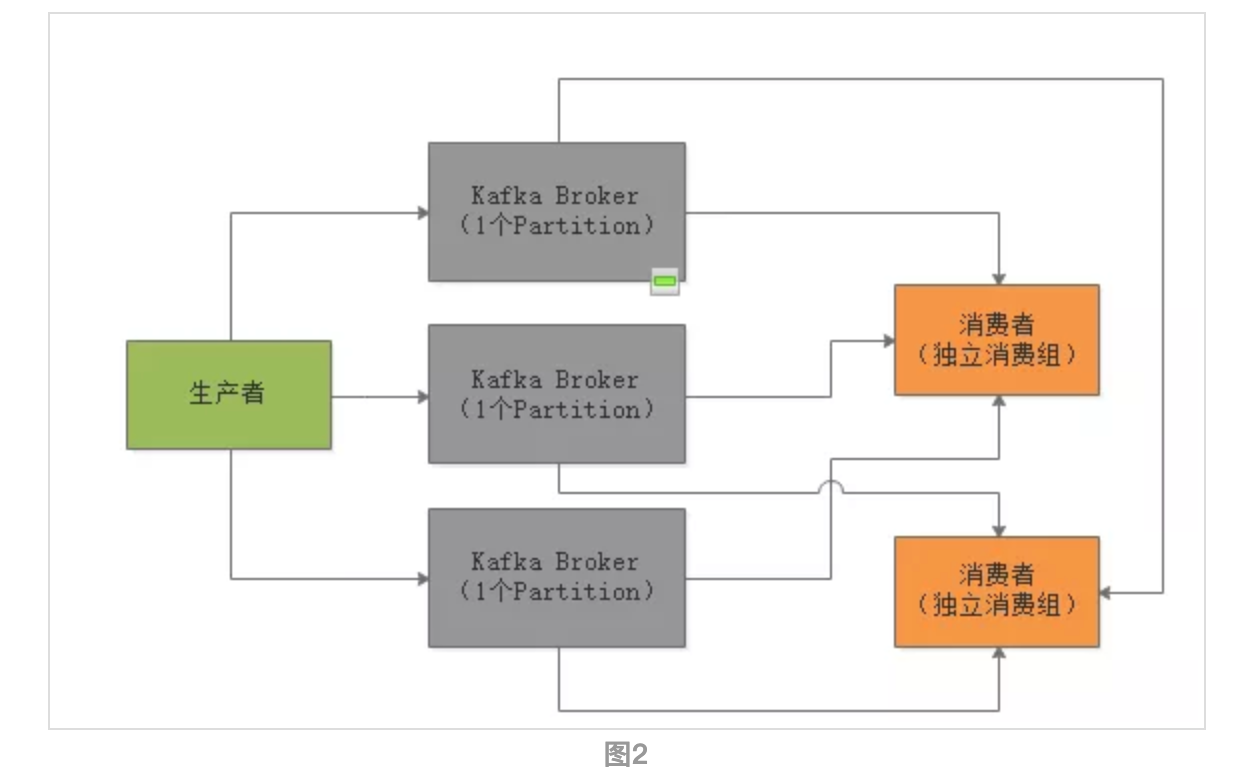
除此之外,kafka就没有任何其他消费功能了,属于一种比较暴力直接的流派
-
有broker的复杂路由
以RabbitMQ为代表,提供非常强大,复杂而且完善的消息路由功能。不是简单的topic-partition消费模型了,引入了 exchange , 根据复杂的业务规则把消息路由到内部的不同queue里去
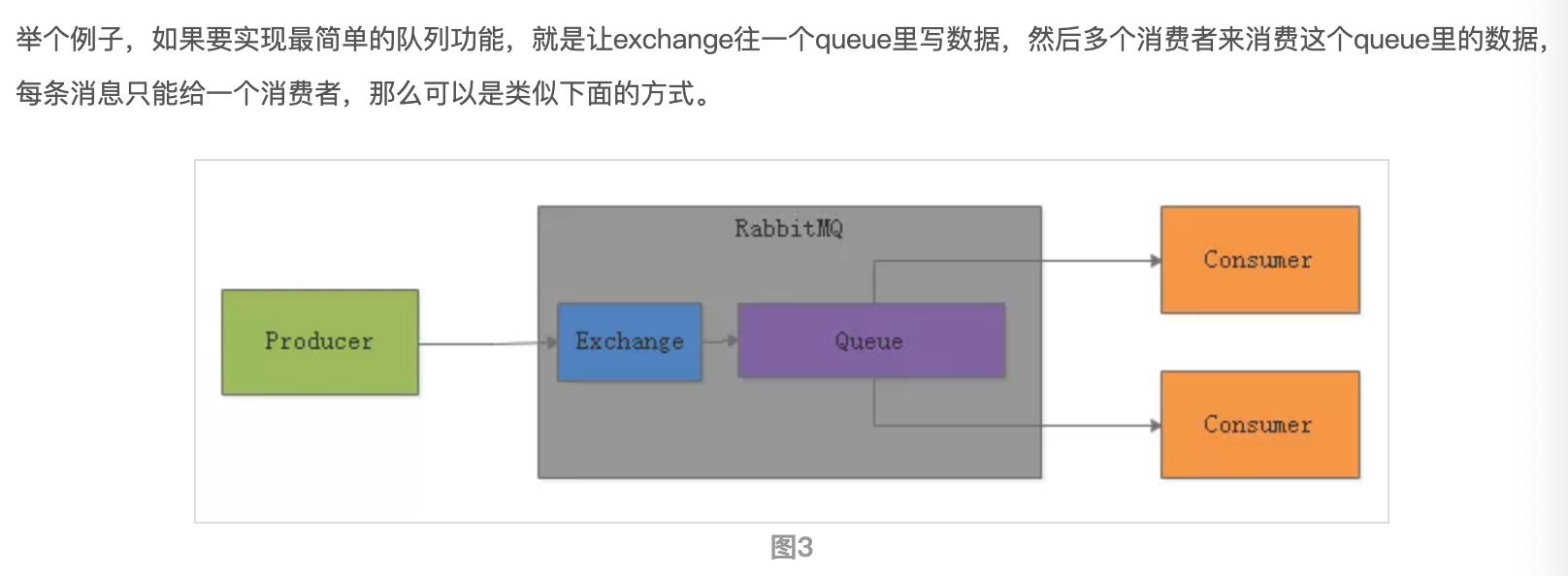
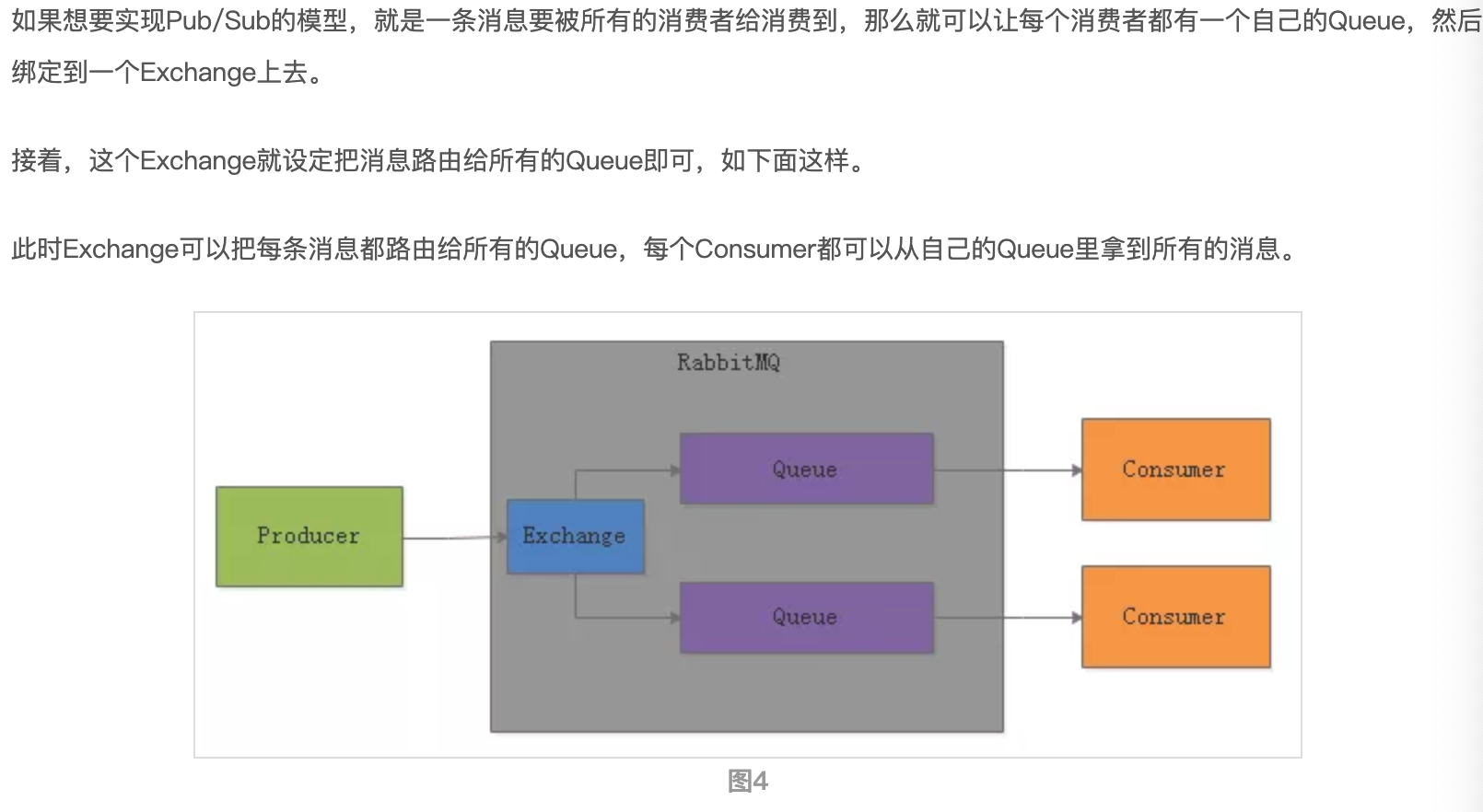
还可以做其他复杂的事情:
如果想某个consumer只能消费到某一类型的数据,那么exchange可以把消息里比如带的XXX前缀的消息路由到某个queue。或者可以限定某个consumer只能消费某一个部分数据
因为这些复杂的消费模型,所以吞吐量比Kafka低一个数量级