1. 前言
本着一个小时一个知识点的理念,如果一天写12个小时,就是12个知识点,这样复习速度就能大幅提升了:)
依赖循环,在前几篇文章中,我都会可以提到,但也是一知半解
我先凭目前的理解说一下
面试题: 说一下依赖循环
- 在初始化bean的时候,首先会实例化该bean所依赖的bean,如果出现a->b b->a这样的情况,就会出现依赖循环,谁都完成不了初始化
- 说完了问题描叙,说说解决,首先要从实例化说起,
new一个类,其实分为俩部分,首先实例化一个不完整的类,第二部再去完整它 。所以要解决依赖循环,就是讲不完整的类先抛出去,让别的需要它的类去使用
马后炮
上面划线的那句话的意思是,java中new一个类的过程,而这里讨论的是spring中初始化bean的过程,是俩回事
但我刚开始写的时候没意识到,spring的中bean的提前引用和完整bean,分别是构造函数实例化 和 注入参数 的俩个状态,参见这篇文章以及总结
下面开始正儿八经的讲解
2. 背景知识
2.1 什么是依赖循环
除了上面说的,重新描述一下 a依赖b b依赖a 的例子
- 发现 a -> b ,去实例化b
- 发现 b->a 容器会获取 a 对象的一个早期引用(early reference) 引入注入到 b 中,让 b 完成实例化
- a 就可以获取到 b 的beandu对象, 随之完成实例化
2.2 spring中的缓存介绍
| 缓存 | 用途 |
|---|---|
| singletonObjects | 用于存放完全初始化好的 bean,从该缓存中取出的 bean 可以直接使用 |
| earlySingletonObjects(早期引用) | 存放原始的 bean 对象(尚未填充属性),用于解决循环依赖 |
| singletonFactories | 存放 bean 工厂对象,用于解决循环依赖 |
2.3 回顾获取bean的过程

这里贴张我在 Spring IOC 容器源码分析(二)- 创建单例 bean 的过程 总结的过程,其中第 1 5 11 步涉及到了上述的缓存singletonObjects singletonFactories
在换种方式去回顾

这里我把大佬的图直接拿过来了
下面是这张图的解释,我觉得很不错,基本就把前几篇的过程总结了一下,看看就能回顾

简化后
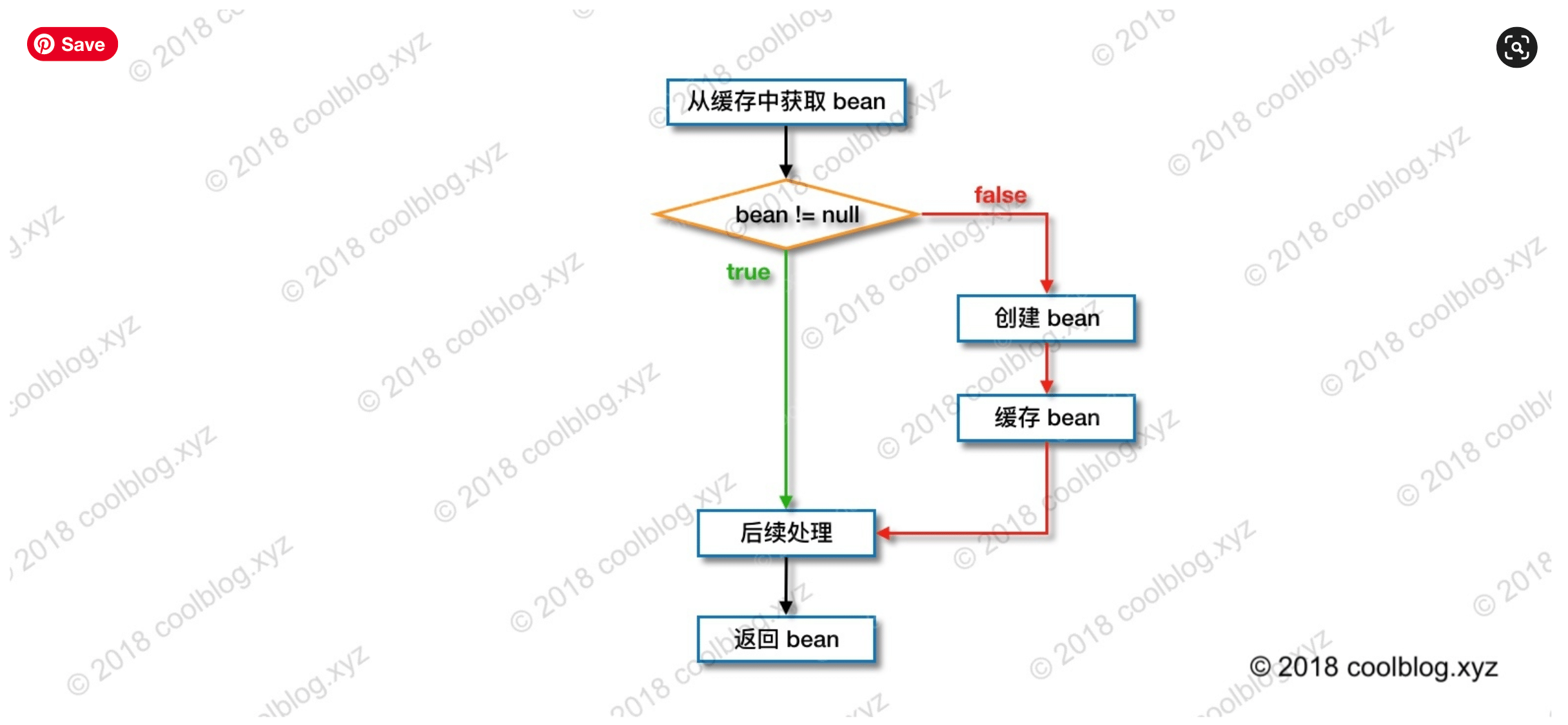
3. 源码分析
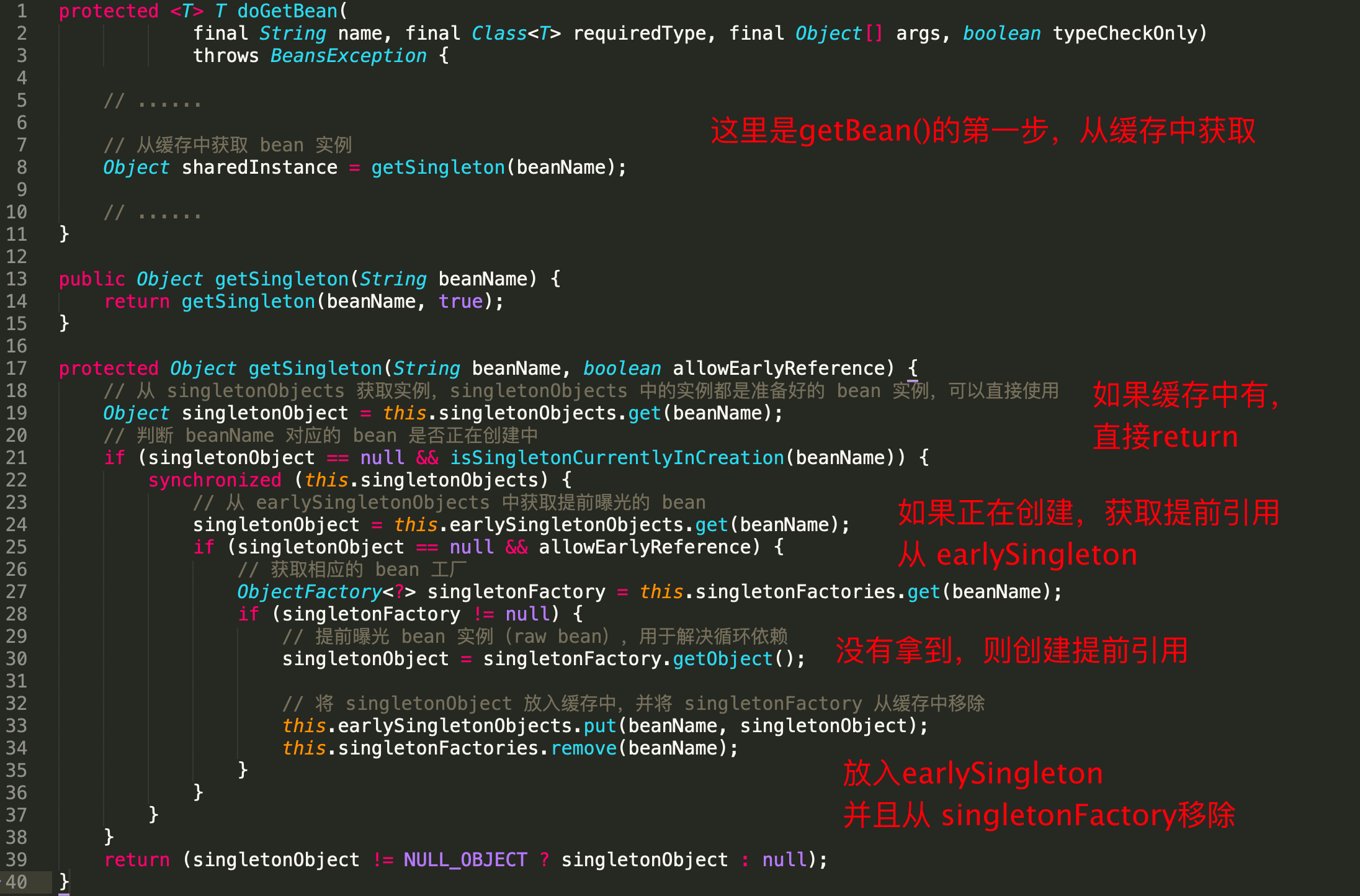
这个还是能看出点东西,除了上图的标识外
一个bean的诞生中,是如何运用上述的三个缓存的
- 首先存放在
singletonFacotries - 然后存放在
earlySingletonObjects并且从singletonFactories移除 - 完全生成后,存放到
singltonObjects,并从上面来个缓存中移除
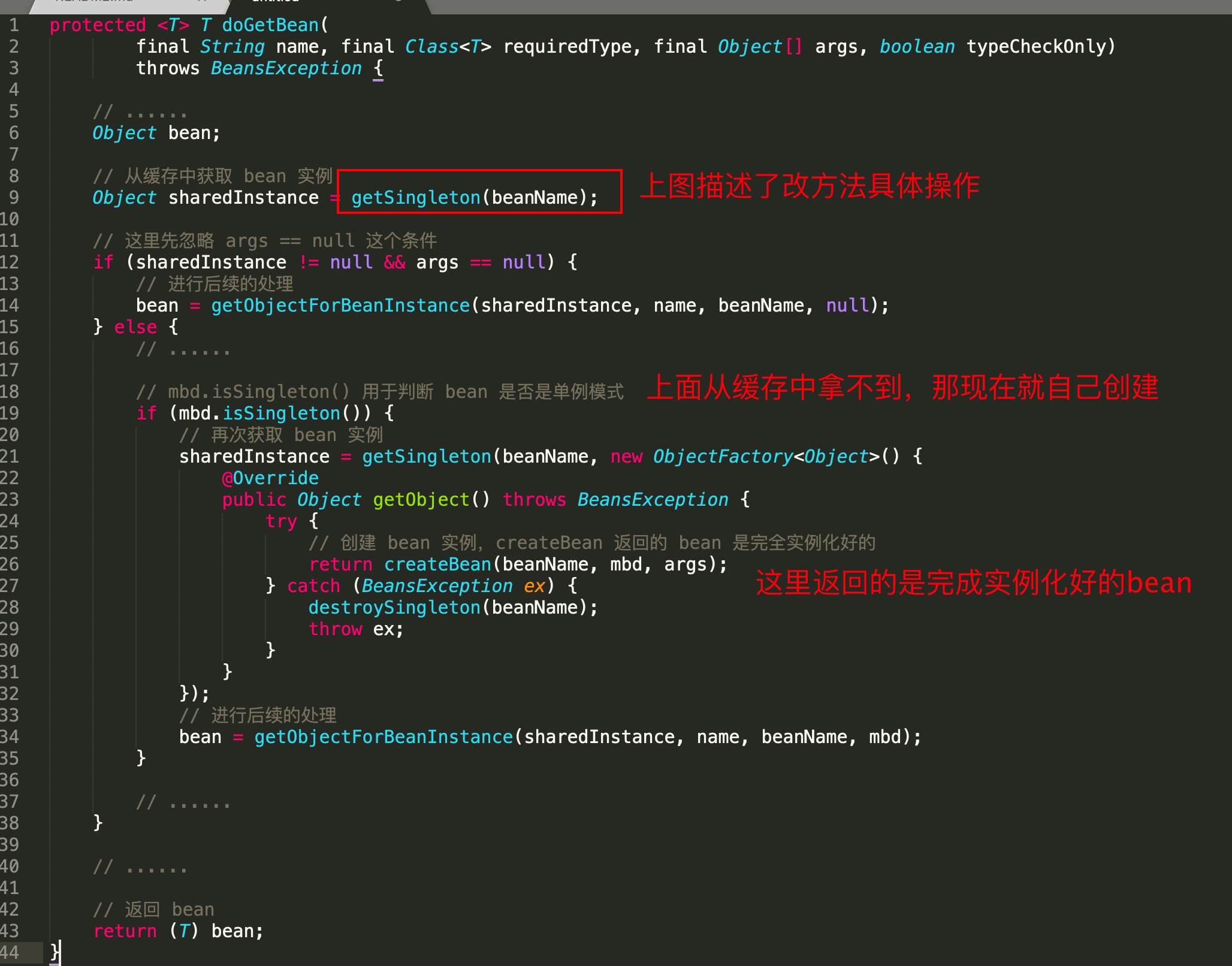
我看到这里,其实是可以详细的知道了,是怎么解决的依赖循环,这里都再继续借用大佬的例子来验证下我的想法对不对
-
创建原始 bean 对象
首先通过Spring-IOC-容器源码分析-三-创建原始-bean-对象中的
createBeanInstance获取原始bean对象,记不起来的话,想想创建bean的3个方式2种策略,通过这个方法,可以创造出一个没有注入参数的提前引用!1 2
instanceWrapper = createBeanInstance(beanName, mbd, args); final Object bean = (instanceWrapper != null ? instanceWrapper.getWrappedInstance() : null);
-
暴露早期引用
1 2 3 4 5 6
addSingletonFactory(beanName, new ObjectFactory<Object>() { @Override public Object getObject() throws BeansException { return getEarlyBeanReference(beanName, mbd, bean); } });
-
解析依赖
1
populateBean(beanName, mbd, instanceWrapper);
populateBean 用于向 beanA 这个原始对象中填充属性,当它检测到 beanA 依赖于 beanB 时,会首先去实例化 beanB。beanB 在此方法处也会解析自己的依赖,当它检测到 beanA 这个依赖,于是调用 BeanFactry.getBean(“beanA”) 这个方法,从容器中获取 beanA。
-
获取早期引用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
protected Object getSingleton(String beanName, boolean allowEarlyReference) { Object singletonObject = this.singletonObjects.get(beanName); if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) { synchronized (this.singletonObjects) { // ☆ 从缓存中获取早期引用 singletonObject = this.earlySingletonObjects.get(beanName); if (singletonObject == null && allowEarlyReference) { ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName); if (singletonFactory != null) { // ☆ 从 SingletonFactory 中获取早期引用 singletonObject = singletonFactory.getObject(); this.earlySingletonObjects.put(beanName, singletonObject); this.singletonFactories.remove(beanName); } } } } return (singletonObject != NULL_OBJECT ? singletonObject : null); }
接着上面的步骤讲,populateBean 调用 BeanFactry.getBean(“beanA”) 以获取 beanB 的依赖。getBean(“beanA”) 会先调用 getSingleton(“beanA”),尝试从缓存中获取 beanA。此时由于 beanA 还没完全实例化好,于是 this.singletonObjects.get(“beanA”) 返回 null。接着 this.earlySingletonObjects.get(“beanA”) 也返回空,因为 beanA 早期引用还没放入到这个缓存中。最后调用 singletonFactory.getObject() 返回 singletonObject,此时 singletonObject != null。singletonObject 指向 BeanA@1234,也就是 createBeanInstance 创建的原始对象。此时 beanB 获取到了这个原始对象的引用,beanB 就能顺利完成实例化。beanB 完成实例化后,beanA 就能获取到 beanB 所指向的实例,beanA 随之也完成了实例化工作。由于 beanB.beanA 和 beanA 指向的是同一个对象 BeanA@1234,所以 beanB 中的 beanA 此时也处于可用状态了。
4. 总结
看下来还是很清楚的,大佬介绍的很详细
那么再问一遍: 讲一讲spring中的循环依赖
- 涉及到的缓存
singletonObjectsearlySingtonObjectssingletonFactries - 创建一个bean首先从缓存中获取,比如先获取(A) 结果就是没拿到
- 首先创建A的早期引用,并且存入
singletonFactories - 对A进行参数注入,发现B,去实例化B
- B再进过从 1-4 的步骤,发现他依赖 A , 从
singletonFactories获取到A的早期引用,然后移入earlySingletonObjects - 创建完整的B 放入
singletonObjects - 从第4步就一直在等B,终于好了,然后愉快的实例化
- 最后实例化好了,放入
singletonObjects
附录